Telehealth platforms have solved the “video visit” problem. Most can reliably connect a patient and a clinician over a stable video stream. However, the industry’s next frontier isn’t about call quality — it’s about what happens during the call.
Voice AI agents are now capable of joining a live telehealth session, listening in real-time, generating clinical documentation, surfacing decision support, and even speaking directly to patients — all within the same WebRTC session that your platform already runs. This isn’t a future roadmap item. It’s happening in production systems in 2025, and it’s becoming the single biggest differentiator between telehealth platforms that scale and those that plateau.
At Trembit, we build real-time communication infrastructure for healthcare clients. We work at the intersection of WebRTC engineering and AI/ML integration, and we’ve seen firsthand how much the architecture decisions made early in this process determine success or failure downstream. This guide is what we wish more development teams had access to before they started.
Why Voice AI Is the 2026 Telehealth Battleground
The economics are simple. A clinician running 20 video visits a day spends roughly 40% of their time on documentation — writing notes, updating records, coding diagnoses. That’s 8 lost hours of clinical capacity per provider per day. Voice AI agents embedded in the call layer don’t just improve the experience; they directly reclaim that time.
Beyond documentation, AI agents running inside live calls enable:
- Real-time clinical decision support — drug interactions, care gap alerts, and protocol reminders surfaced the moment they’re relevant.
- Automated triage scoring — risk signals identified and flagged during the call, not after.
- Post-visit summaries generated before the call ends — SOAP notes, after-visit instructions, referral drafts.
- Multilingual support — AI-assisted translation that doesn’t require a third-party interpreter line.
- Patient engagement monitoring — detecting confusion, distress, or disengagement from voice patterns.
Every one of these capabilities lives or dies on the quality of the underlying WebRTC + AI integration. That’s where most implementations struggle.
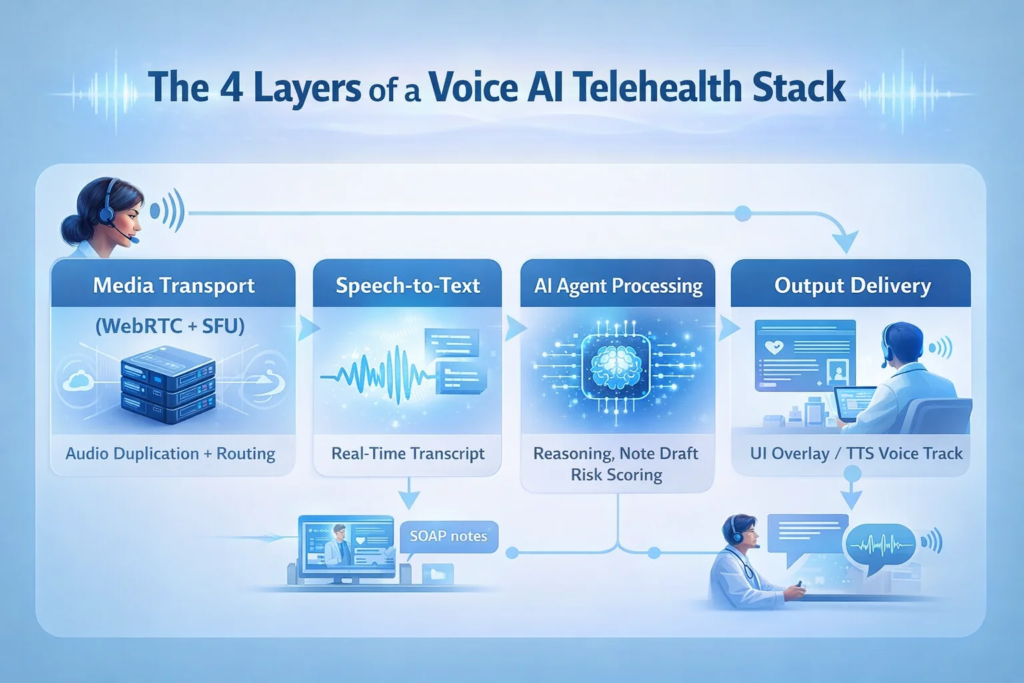
The Four Layers of a Voice AI Telehealth Stack
Understanding the architecture means understanding the pipeline. Audio doesn’t travel from a patient’s microphone to an AI model in one step — it moves through a chain of components, each of which introduces latency and potential failure.
Here is how a production system is structured:
Layer 1: Media Transport (WebRTC + SFU)
A direct peer-to-peer WebRTC connection cannot easily be tapped for AI processing. Production Voice AI systems require a Selective Forwarding Unit (SFU) — a media server that receives audio and video tracks from each participant and can route copies to downstream consumers, including your AI pipeline.
Popular SFU choices include LiveKit, mediasoup, Janus, and LiveKit Cloud. The key capability you need: the ability to programmatically extract an audio track from a participant and forward it to an external service in real time, with configurable codec handling.
Layer 2: Speech-to-Text (STT)
The raw audio stream from the SFU is passed to a streaming STT engine. Options vary significantly in accuracy, latency, and healthcare vocabulary support:
| STT Provider | Latency | Medical Vocabulary | Self-Hosted Option | Best For |
| Deepgram Nova-2 | ~200–300ms | Strong | No (API) | Speed-critical active agents |
| AssemblyAI | ~300–500ms | Good | No (API) | Ambient scribe workloads |
| Google Medical STT | ~400–600ms | Excellent | No (API) | Clinical terminology accuracy |
| OpenAI Whisper (self-hosted) | Variable | Moderate | Yes | HIPAA-strict / air-gapped environments |
| Azure Cognitive Speech | ~300–500ms | Good | No (API) | Microsoft/Azure EHR ecosystems |
For ambient scribing use cases, 500ms latency is acceptable. For interactive voice agents that respond in the call, you need STT latency under 300ms — or your conversational flow will feel broken.
Layer 3: AI Agent Processing
The transcript feeds into a language model that performs clinical reasoning: generating note drafts, extracting structured data, scoring risk, or formulating a conversational response. This is where your clinical intelligence lives.
Key design decisions at this layer:
- Context injection — the model needs the patient’s medical history, current medications, and visit reason before the call starts, not just the live transcript
- Structured output — clinical notes should be generated in formats compatible with your EHR’s FHIR API, not as free text; the provider must reformat
- Confidence thresholds — AI suggestions flagged with low confidence should be visually distinguished in the provider UI
Layer 4: Output Delivery
AI output reaches clinicians and patients through two channels:
- Screen overlays — real-time transcription, suggested note drafts, and decision support are displayed in the provider UI without audio.
- Voice synthesis — for active agents that speak, Text-to-Speech (TTS) output is synthesized and re-injected into the SFU as a new audio track.
The voice injection path requires end-to-end latency under 1,500ms for the interaction to feel natural. Achieving this in production requires careful optimization at every layer.
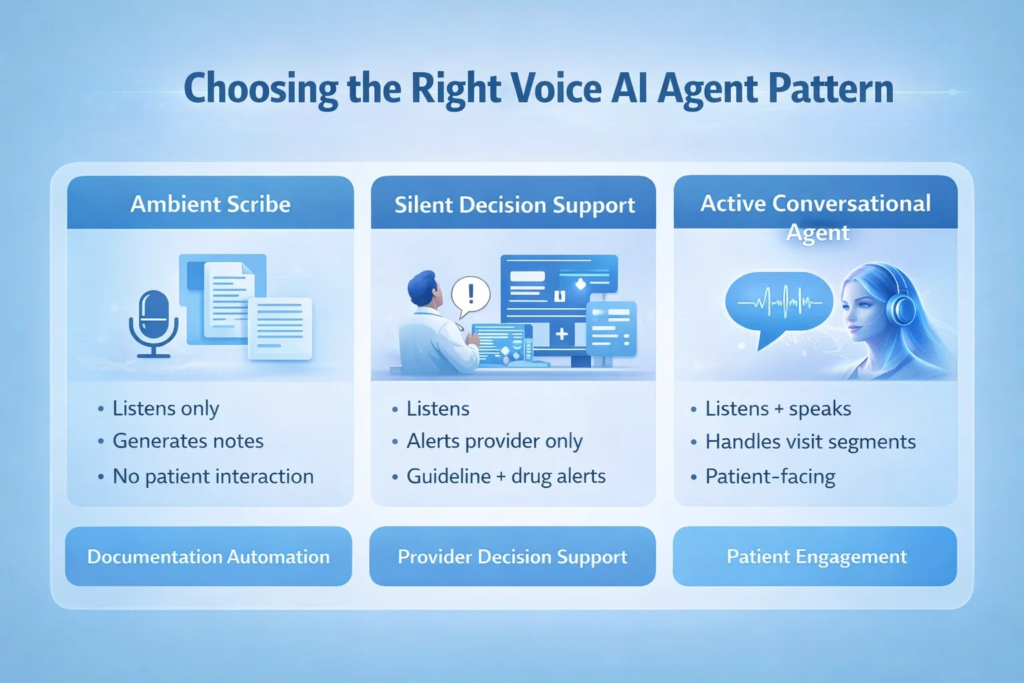
Three Agent Patterns: Choosing the Right Fit
Not every telehealth use case needs the same AI behavior. These are the three patterns Trembit recommends mapping to clinical workflows before writing a single line of integration code:
1. Ambient Scribe Agent
Listens. Doesn’t speak. Documents.
The AI observes the entire visit and generates a structured clinical note — SOAP format, ICD codes, CPT suggestions — delivered to the provider before they’ve closed the call window. No patient interaction. No AI voice. Zero disruption to clinical rapport.
Best for: Primary care, urgent care, behavioral health, and any high-volume visit environment.
2. Silent Decision Support Agent
Listens. Surfaces information to the provider only.
The AI monitors the transcript and pushes real-time alerts and information to the provider’s screen: flagging a potential drug interaction when a new medication is mentioned, surfacing a relevant clinical guideline, or alerting that a patient hasn’t had a recommended screening. The patient never knows the AI is present.
Best for: Specialist consultations, complex chronic disease management, care gap closure programs.
3. Active Conversational Agent
Listens. Speaks. Participates.
The AI joins the call as an audible participant, handling defined segments of the visit — medication adherence review, symptom collection, patient education — and handing off to the clinician for clinical judgment. Fully disclosed to the patient. Often preferred for routine follow-ups.
Best for: Medication management, post-discharge follow-up, chronic care check-ins, triage pre-screening.
What Production Readiness Actually Requires
Teams underestimate the non-AI work involved in these integrations. Here is what a production-grade implementation needs beyond the core AI pipeline:
HIPAA-compliant data handling end-to-end. Every audio stream, transcript fragment, and AI output is PHI. BAAs must be in place with every vendor in the pipeline — STT providers, LLM APIs, and cloud infrastructure. Self-hosted models eliminate some vendor risk but introduce their own compliance surface.
Graceful degradation: The call must continue if the AI layer goes offline. Build circuit breakers that detect AI pipeline failure and allow the visit to proceed as a standard video call, with an alert to the provider.
Audio preprocessing Voice AI accuracy is highly sensitive to audio quality. Acoustic echo cancellation (AEC), noise suppression, and automatic gain control must be implemented at the WebRTC client layer before audio reaches the STT pipeline. Skipping this consistently produces transcription accuracy 10–15% below what’s achievable.
Provider UX design Clinical AI that requires a provider to change their workflow will not be adopted. The most successful implementations surface AI output in-context — inside the EHR interface, inside the video call UI — rather than in a separate tab or window.
Patient consent flows. In most jurisdictions, patients must be informed when an AI agent is present in their care encounter. This consent flow must be built into your visit onboarding, stored, and auditable.
The Mistakes That Kill These Projects
Based on Trembit’s experience with healthcare clients navigating this integration:
- Starting with P2P WebRTC — Direct peer connections cannot be easily modified to support AI media tapping without a full re-architecture. Build on an SFU from day one.
- Treating AI as a bolt-on — Voice AI integration touches media infrastructure, EHR systems, clinical workflows, and compliance processes simultaneously. It cannot be handed to a single team as a side project.
- Optimizing accuracy before latency — For interactive agents, a 97%-accurate response that takes 3 seconds is worse than a 93%-accurate response that takes 0.8 seconds. Latency is the first constraint to solve.
- Skipping clinical validation — AI-generated documentation must be reviewed with real clinicians before deployment. Note formats, terminology preferences, and alert thresholds vary enormously by specialty and will not be correct out of the box.
How Trembit Approaches This
Trembit brings both WebRTC engineering depth and AI/ML capability to these projects, which matters because the hard problems here live at the intersection of both disciplines. Getting STT latency to 250ms requires WebRTC expertise. Getting clinical note quality to the point where providers trust and use it requires ML expertise. Most vendors have one; few have both.
A typical Trembit Voice AI telehealth engagement runs 14–20 weeks from architecture to production launch, covering SFU configuration, STT pipeline setup, AI agent design, EHR integration, provider UI, compliance infrastructure, and a supervised pilot with real clinicians before full rollout.
If you’re evaluating Voice AI integration for your telehealth platform — whether you’re starting from scratch or adding AI to an existing WebRTC product — the architecture decisions you make in the first two weeks will shape everything that follows.
Trembit’s engineering team is available for technical consultation and scoping. [Get in touch → here]