If you’re reading this, you’re probably already past the “should we migrate?” question. Maybe Twilio sent a deprecation notice on a product you rely on. Maybe your per-minute costs crossed a threshold that’s hard to justify. Maybe Vonage’s acquisition by Ericsson has you worried about roadmap continuity. Or maybe you’ve simply hit a ceiling — features your product needs that your current vendor won’t build.
Whatever the trigger, telehealth platform migrations are high-stakes. You’re moving the infrastructure that connects patients with clinicians. Downtime isn’t a UX problem — it’s a care continuity problem. That reality shapes everything about how a migration should be planned and executed.
This guide is what Trembit shares with clients when they come to us with a migration mandate. It covers the technical architecture decisions, the sequencing, the traps, and the testing approach that makes the difference between a clean cutover and a six-month fire drill.
Why Telehealth Teams Are Leaving Twilio and Vonage Right Now
The migration wave is real, and the reasons are consistent across the clients Trembit works with:
Twilio-specific triggers:
- Twilio Video’s shift away from active development in favor of partnerships (notably with Zoom) left many healthcare teams without a clear product roadmap.
- Pricing at scale — Twilio’s participant-minute model becomes expensive past ~500K minutes/month with limited enterprise negotiation leverage
- Limited native support for AI agent integration and real-time media processing, which is increasingly table-stakes for telehealth
- The 2022 data breach and subsequent trust erosion in security-conscious healthcare organizations
Vonage-specific triggers:
- Ericsson’s acquisition created genuine uncertainty about the Video API product’s long-term investment and support.
- Vonage’s pricing model and API design lag behind newer entrants, particularly for WebRTC-native use cases.
- Support quality has degraded for mid-market customers since the acquisition.
Common to both:
- Neither vendor was built ground-up for healthcare; HIPAA compliance is bolted on rather than native.
- Neither has strong native AI/ML media processing support, as Voice AI becomes a product requirement.
- Both charge premium prices for capabilities that open-source and newer managed platforms now offer at a lower cost.
Choosing Your Migration Target
Before planning a migration, you need to know where you’re going. The decision is not just about replacing like-for-like — it’s an opportunity to re-architect for the next three years of your product.
| Platform | Best For | Pricing Model | Self-Host Option | AI/Agent Support | HIPAA BAA |
| LiveKit Cloud | Modern WebRTC, AI-first products | Per participant-minute | Yes (open source) | Native (Agents API) | Yes |
| Daily.co | Fast integration, strong reliability | Per participant-minute | No | Moderate | Yes |
| AWS IVS / Chime | AWS-native ecosystems | Usage-based | Partial | Via AWS services | Yes |
| Telnyx | Voice/PSTN-heavy telehealth | Per minute/channel | No | Moderate | Yes |
| mediasoup (self-hosted) | Maximum control, high volume | Infrastructure only | Yes (only) | Custom build required | Self-managed |
| 100ms | Healthcare/enterprise video | Per participant-minute | No | Moderate | Yes |
Trembit’s current default recommendation for telehealth migrations is LiveKit — either LiveKit Cloud for teams under 1M participant-minutes/month, or self-hosted LiveKit for larger platforms. The combination of open-source transparency, native AI agent support, competitive pricing, and an active development roadmap makes it the most defensible choice for healthcare products being built for 2026 and beyond.
That said, if your telehealth platform is deeply PSTN-integrated — recording calls to phone lines, supporting patients on landlines — Telnyx deserves serious evaluation. Their voice infrastructure is significantly more robust than Twilio’s at comparable price points, and the migration path from Twilio’s voice APIs is well-documented.
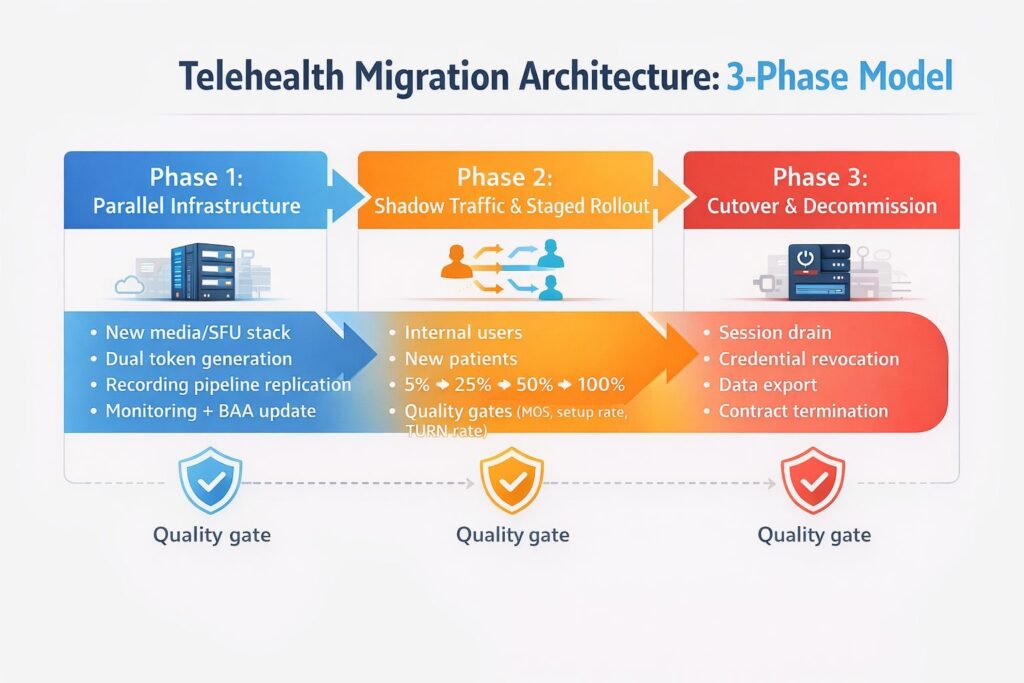
The Migration Architecture: Three Phases That Actually Work
Migrations fail when they’re treated as lift-and-shift operations. Telehealth video infrastructure is not a database you can export and import. Sessions are stateful, credentials are per-session, and your frontend, backend, and infrastructure are all coupled to your current vendor in ways that aren’t obvious until you start pulling threads.
The phased architecture Trembit uses:
Phase 1: Parallel Infrastructure (Weeks 1–4)
Stand up your new platform infrastructure alongside your existing stack. Do not touch production traffic yet.
What happens in this phase:
- New SFU/media infrastructure deployed and configured.
- Signaling layer abstracted behind a vendor-agnostic interface in your backend.
- Session token generation updated to support both old and new platforms simultaneously.
- Recording pipeline replicated on new infrastructure.
- HIPAA documentation updated: new BAA executed, security review completed.
- Monitoring and alerting are configured for the new platform.
The goal: by the end of Phase 1, your new infrastructure can handle a complete telehealth session end-to-end. No production traffic has moved.
Phase 2: Shadow Traffic and Staged Rollout (Weeks 4–8)
Begin routing real traffic to the new platform, starting with the lowest-risk cohort and expanding based on quality metrics.
Recommended rollout sequence:
- Internal users and test accounts — catch configuration issues with zero patient impact
- New patient registrations only — existing patients stay on the old platform; new sessions on the new platform.
- 5% of all sessions — random sample, monitor call quality metrics against baseline
- 25% → 50% → 100% — expand in increments of 2–4 weeks each, with quality gates between stages
Quality gates before each expansion:
- Call setup success rate ≥ 98.5% (matching or exceeding current platform baseline)
- Mean call quality score (MOS) within 5% of the current platform
- TURN relay rate ≤ 30%
- P95 call setup latency ≤ 3 seconds
- Zero incidents of PHI handling failures or BAA-scope data leakage
Phase 3: Cutover and Decommission (Weeks 8–12)
Once 100% of new sessions route to the new platform, existing in-flight sessions on the old platform need to be completed before you can decommission credentials and infrastructure.
What this phase requires:
- Session drain period: allow all active sessions on the old platform to complete naturally (typically 24–72 hours)
- Credential revocation: systematically retire old platform API keys, room tokens, and webhook endpoints
- Historical data: export and archive session logs, recording metadata, and quality metrics from the old platform before account closure
- Contract termination: most enterprise agreements require 30–90 days’ written notice; serve this at the start of Phase 3, not the end
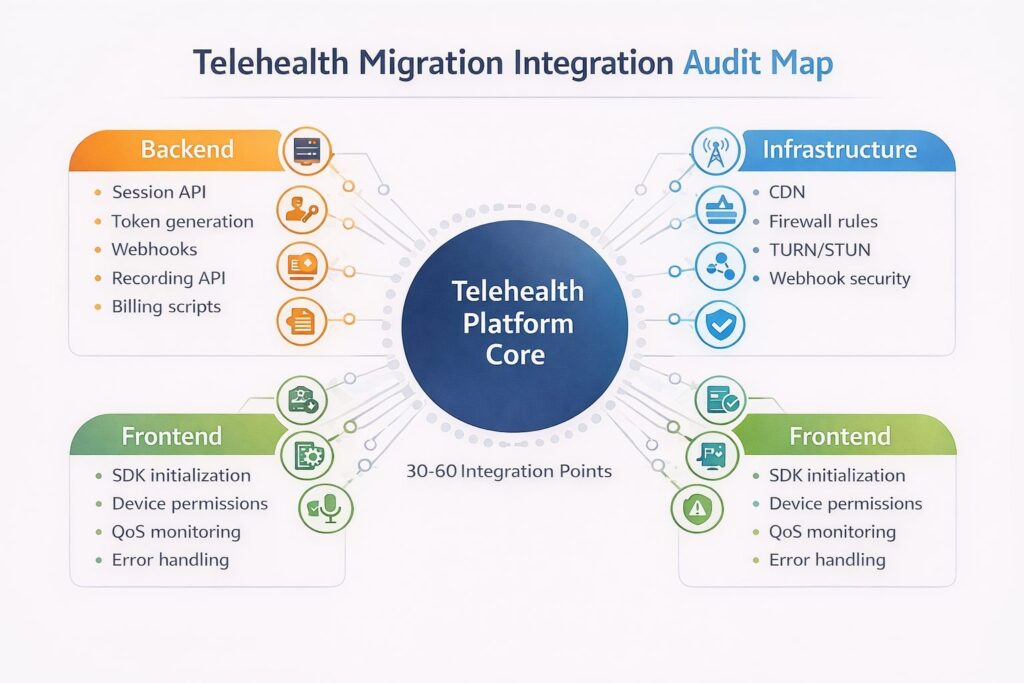
The Integration Points You Need to Audit Before You Start
The most common source of migration surprises is undocumented integration points — places where your codebase touches the old vendor that aren’t obvious from the main session flow. Before writing a line of migration code, run this audit:
Backend integrations to find:
- Session/room creation API calls
- Participant token generation
- Webhook handlers (session start/end events, participant join/leave, recording complete)
- Recording API calls (start, stop, fetch, delete)
- Composition/layout API calls if you use a cloud-based recording layout.
- Usage reporting and billing reconciliation scripts
- Any scheduled jobs that query session data
Frontend integrations to find:
- SDK imports and initialization code
- Device permission handling (often vendor-specific quirks)
- Network quality monitoring and display
- Custom UI components built on vendor-specific APIs
- Error handling that references vendor-specific error codes
Infrastructure integrations to find:
- CDN configuration for media delivery
- Firewall rules that allow/block vendor-specific IP ranges or domains
- TURN/STUN server configuration
- Webhook endpoint security (IP allowlisting for vendor callback IPs)
A thorough audit of a mid-size telehealth platform typically surfaces 30–60 distinct integration points. Teams that skip this step routinely discover 15–20 additional points during migration, each of which extends the timeline.
What Goes Wrong: The Migration Failure Patterns
Trembit has been brought in to rescue migrations in progress as often as we’ve been engaged to run them from the start. The failure patterns are consistent:
The “Big Bang” cutover. Teams attempt to move all traffic from old to new platforms in a single deployment. Any issue — and there will be issues — affects 100% of sessions immediately. In telehealth, that means patient visits fail in real time. Always use a staged rollout.
Token/credential race conditions. In hybrid periods where both platforms are active, session tokens must be clearly scoped to the platform they belong to. Backend systems that generate tokens must be stateful about which platform a given session is on. Mixing tokens across platforms is a common source of mysterious call failures that are very hard to debug.
Recording pipeline neglect. Teams focus migration effort on the live call path and treat recording as secondary. Recording pipelines are often more tightly coupled to vendor APIs than the live call path, and recording failures in telehealth have compliance implications — visit documentation requirements mean a failed recording is not just a missing file.
Insufficient TURN coverage on new platforms. New TURN infrastructure frequently has gaps in geographic coverage or capacity. A platform that worked perfectly in testing (conducted from offices with good network connectivity) can have high failure rates in production (patients connecting from home networks, mobile data, VPNs). Stress test your TURN infrastructure explicitly before expanding rollout.
Forgetting the contract. Enterprise agreements with Twilio and Vonage often have minimum commitment clauses and termination notice requirements. Teams that move all traffic before serving proper notice continue paying for both platforms simultaneously. Read the contract before you start the migration.
Timeline and Resource Reality Check
A well-executed telehealth platform migration requires:
| Phase | Duration | Engineering Resources |
| Audit and planning | 2 weeks | 1 senior engineer + architect |
| Phase 1: Parallel infrastructure | 3–4 weeks | 2 engineers full-time |
| Phase 2: Staged rollout | 4–6 weeks | 1 engineer + QA coverage |
| Phase 3: Cutover and decommission | 2–3 weeks | 1 engineer part-time |
| Total | 11–15 weeks | ~3–4 FTE-months |
Teams consistently underestimate this. The engineers who know your current integration best are also the ones needed to build the new one — and they have other work. Build in a buffer, and be honest with your organization about the timeline before you commit publicly to a migration date.
How Trembit Approaches Telehealth Migrations
Migration projects are a significant part of Trembit’s work — and they’re projects where the cost of mistakes is real. We bring both WebRTC infrastructure depth and healthcare domain experience: understanding how a failed session during a psychiatric evaluation is different from a failed session during a shopping consultation matters for how you design your fallback behavior and your rollout sequencing.
Our migration engagements typically begin with a two-week technical audit — mapping every integration point, documenting the current architecture, and producing a migration plan with realistic timelines before any code is written. That investment consistently prevents the mid-migration discoveries that extend timelines and create production incidents.
If you’re evaluating a migration off Twilio or Vonage and want a second opinion on your current plan — or a ground-up assessment of what the migration will actually take — Trembit’s engineering team is available for consultation.