
Language barriers in healthcare aren’t a niche problem. More than 25 million people in the United States have limited English proficiency, and research consistently shows that patients who can’t communicate fluently with their providers experience worse outcomes, more medical errors, and significantly lower satisfaction with their care. In telehealth, where the entire clinical relationship runs through a video call, language access isn’t a feature — it’s an equity and compliance requirement.
The architecture challenge is harder than it looks. Real-time medical interpretation in a live video call has to be fast enough not to destroy the clinical conversation, accurate enough to be trusted with diagnoses and medication instructions, and scalable enough to cover the languages your patient population actually speaks — not just Spanish and French.
Trembit has built real-time translation infrastructure for telehealth platforms operating at scale across 250+ languages, including work on systems that support medical-grade interpretation for diverse patient populations. This article documents what we’ve learned about architecture patterns, trade-offs, and what it actually takes to make translation work in a production clinical environment.
Why Telehealth Translation Is Architecturally Different From Everything Else
If you’ve built a translation into a document editor or a customer support chat, the telehealth version will surprise you. The constraints are different in almost every dimension:
Latency tolerance is measured in hundreds of milliseconds, not seconds. A translation that takes 2 seconds in a chat interface is fine. The same latency in a live conversation creates an interaction that feels broken — patients talk over the translation, clinicians lose the thread of the conversation, and the clinical rapport that makes telehealth work evaporates. Production systems need end-to-end translation latency under 800ms for the experience to feel natural.
Accuracy requirements are clinical, not conversational. A mistranslation in a consumer app is an annoyance. A mistranslation of a medication dosage, a symptom description, or a consent explanation can harm a patient. Medical terminology, drug names, anatomical references, and dosage instructions require specialized vocabulary handling that general-purpose translation models often get wrong.
You’re translating speech, not text. The pipeline starts with audio from a live WebRTC session, not a typed input. Speech recognition quality — especially for non-native speakers, patients with accents, or patients in noisy environments — directly determines translation quality downstream. A bad transcript produces a bad translation regardless of how good your translation model is.
The regulatory context is real. Title VI of the Civil Rights Act requires healthcare organizations receiving federal funding to provide meaningful language access. HIPAA applies to audio and text at every stage of the pipeline. And in many states, medical interpretation requires human interpreter involvement for certain clinical scenarios — your architecture needs to support graceful handoff to human interpreters when required.
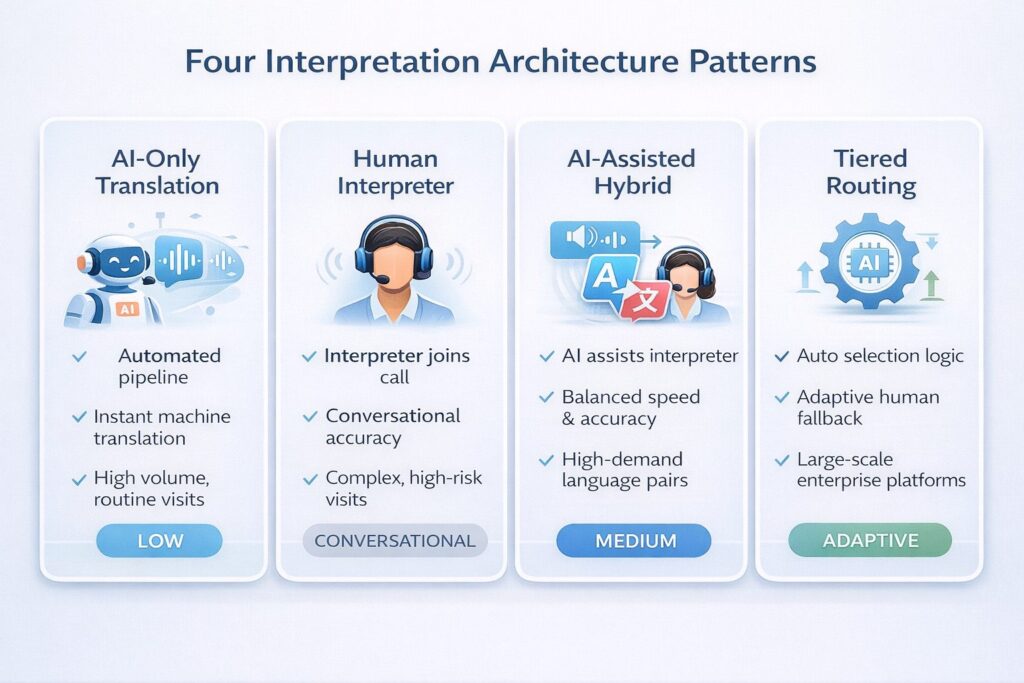
The Four Architecture Patterns
There is no single “right” architecture for real-time telehealth translation. The right pattern depends on your language coverage requirements, your latency constraints, your accuracy requirements, and whether your use case involves AI translation, human interpreters, or both.
Pattern 1: AI-Only Streaming Translation
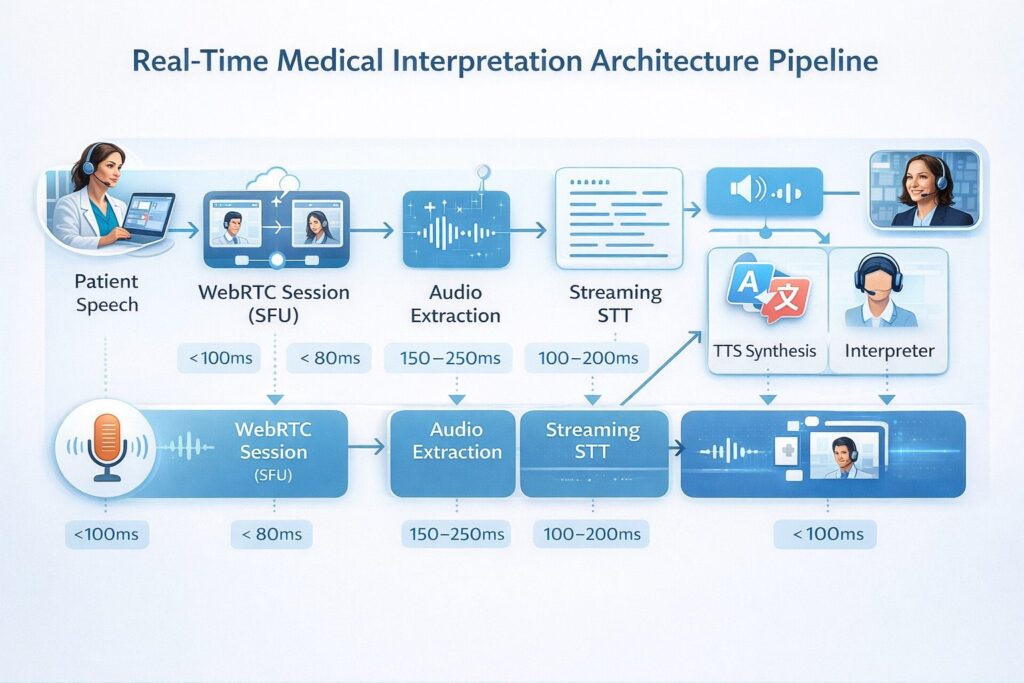
How it works: Audio from the WebRTC session is streamed to a speech-to-text engine, the transcript is fed to a machine translation API, and the translated text (or synthesized speech) is returned to the call in near-real time.
Pipeline: WebRTC SFU → Audio stream extraction → Streaming STT → Machine translation API → TTS synthesis → Re-injection into call
Latency profile: 400–900ms end-to-end with optimized component selection
Best for: High-volume, lower-acuity interactions where speed matters more than medical precision — appointment scheduling, medication refill confirmations, symptom triage for common conditions, post-visit follow-up calls.
Limitations: General-purpose MT models make medical terminology errors that are clinically unacceptable for complex visits. Not appropriate as the sole translation method for differential diagnosis, informed consent, or complex medication management.
Pattern 2: Human Interpreter on Demand (OPI/VRI Integration)
How it works: A human medical interpreter joins the WebRTC session as a third participant — either via Voice (OPI, over-phone interpretation) bridged into the call, or as a Video Remote Interpreter (VRI) with their own video stream. The interpreter handles real-time translation between the patient and clinician.
Pipeline: Standard WebRTC session + interpreter scheduling/dispatch system + PSTN or WebRTC interpreter connection
Latency profile: Human conversation pace — no additional technical latency, but the consecutive interpretation model means each statement takes 2x as long
Best for: Complex clinical conversations, informed consent, mental health visits, high-acuity presentations, and languages where AI accuracy is insufficient.
Limitations: Cost ($2–$6/minute for professional medical interpretation), availability latency (connecting an interpreter adds 2–5 minutes to visit start), and scheduling complexity at scale.
Pattern 3: AI-Assisted Human Interpretation (Hybrid)
How it works: AI translation runs in the background during the call, providing a real-time transcript and translation overlay to the interpreter — reducing cognitive load and improving accuracy. The human interpreter remains the authoritative voice in the call; the AI provides a second layer of support.
Pipeline: Pattern 1 pipeline running in parallel with Pattern 2, with AI output delivered to the interpreter’s interface only
Best for: Medical interpretation services that want to improve interpreter efficiency and quality, complex visits in high-demand language pairs.
Limitations: Complexity and cost of both layers simultaneously; requires interpreter interfaces designed for AI-assisted workflows.
Pattern 4: Tiered Routing by Clinical Context
How it works: The platform automatically routes to different translation approaches based on visit type, language pair, and clinical risk signals. Routine follow-ups use AI translation; new patient visits, consent discussions, and complex presentations trigger human interpreter dispatch.
Pipeline: Session metadata + ML routing logic → Pattern 1 or Pattern 2 based on routing decision
Best for: At-scale telehealth platforms serving diverse populations where neither pure AI nor pure human interpretation is operationally or economically feasible for all visits.
This is the architecture Trembit recommends for most enterprise telehealth deployments. It optimizes cost and speed for the visits where AI is safe to use, while ensuring human interpreter quality for the visits where accuracy is clinically critical.
Component Selection: What Actually Works at Scale
The component decisions that most determine system quality:
Speech-to-Text for Non-English Speakers
This is the most under-invested layer in most translation implementations. STT accuracy for accented speech and non-native English varies enormously across providers — and for a pipeline where the transcript feeds directly into translation, STT errors compound.
| STT Provider | Language Coverage | Accent Handling | Medical Vocabulary | Streaming Latency |
| Deepgram | 30+ languages | Strong | Good (with custom models) | ~200–300ms |
| Google Speech-to-Text | 125+ languages | Very strong | Excellent (Medical API) | ~300–500ms |
| Azure Cognitive Speech | 100+ languages | Strong | Good | ~300–500ms |
| AssemblyAI | 17 languages | Moderate | Moderate | ~300–500ms |
| AWS Transcribe Medical | English + Spanish | Moderate | Excellent | ~400–600ms |
| OpenAI Whisper (self-hosted) | 99 languages | Very strong | Moderate | Variable |
For 250+ language coverage, Google Speech-to-Text with the Medical API is the most complete solution for the STT layer. For self-hosted requirements in HIPAA-strict environments, Whisper large-v3 with medical fine-tuning is the best available option — though it requires real infrastructure investment to run at production latency.
Machine Translation for Medical Content
General-purpose MT APIs (Google Translate, DeepL) produce high-quality output for common language pairs in everyday language. For medical content, the gaps appear in drug nomenclature, anatomical terminology, dosage expression, and idiomatic symptom descriptions.
Mitigation strategies Trembit implements in production:
- Medical terminology glossaries injected into translation prompts — curated lists of drug names, anatomical terms, and clinical phrases that should be translated using specific target-language equivalents
- Post-translation validation for high-risk content types (medication instructions, dosage information) using a secondary model pass that flags potential mistranslations
- LLM-based translation (GPT-4, Claude) for complex or ambiguous content, with rule-based MT for high-speed/lower-risk content — the two-tier model balances latency and accuracy
TTS for AI Voice Output
When the AI speaks rendered content back into the call rather than displaying text:
- Voice naturalness matters clinically — robotic-sounding speech increases patient anxiety and reduces comprehension.
- Language-native prosody (not just vocabulary) is required for patient trust; a technically correct translation delivered with wrong stress patterns sounds wrong to native speakers.
- ElevenLabs, Azure Neural TTS, and Google WaveNet are the current leaders for natural-sounding multilingual synthesis.
- Synthesis latency adds 200–400ms to the pipeline — this must be budgeted in your total latency target.
The Technical Requirements Nobody Mentions
Silence Detection and Turn Management
In a monolingual call, WebRTC handles audio naturally — participants talk, others listen. In a translated call, there is a third “speaker” (the interpreter or TTS output), and the system must manage when each participant’s audio is active. Poor turn management produces audio collisions — the interpreter speaks over the patient, or the TTS output triggers while the clinician is still talking.
Production systems need explicit voice activity detection (VAD) with translation-aware turn logic: the AI translation pipeline should not begin output until the source speaker has finished, with configurable silence threshold tuning per language (some languages have longer natural pause patterns than others).
Transcript Availability and Dual-Language Documentation
A translated telehealth session should produce documentation in both languages — source and target. The original-language transcript is the legal record; the translated version supports care coordination and patient access. Your architecture should store both, linked to the session record, with clear provenance metadata (AI-generated vs. human-interpreted).
Language Detection and Switching
Patients don’t always know in advance what language they’ll need. Your system should support automatic language detection during the first 10–15 seconds of a session, with dynamic switching to the correct translation pipeline. This is especially important for patients who are bilingual but more comfortable discussing specific topics (symptoms, medications) in their first language.
What 250+ Languages in Production Actually Requires
Running real-time translation at 250+ language coverage — as Trembit has done in production for healthcare clients — surfaces operational realities that architecture diagrams don’t capture:
- Long-tail language support is not uniform. The top 20 languages account for roughly 80% of usage volume. Languages 21–250 have much lower volume but often higher clinical risk — patients using rare languages are frequently more isolated, have less access to in-person interpretation, and are more dependent on your system working correctly.
- Quality monitoring must be language-specific. Aggregate translation quality metrics obscure per-language degradation. A system that’s 95% accurate on average can be 75% accurate on Somali or Tigrinya — and you won’t know unless you’re measuring at that level.
- Human interpreter dispatch coverage must match your language list. If your AI translation covers 250 languages but your on-demand human interpreter network only covers 40, your tiered routing logic is only effective for those 40. Interpreter network partnerships are an operational dependency, not just a technical one.
How Trembit Approaches Translation Infrastructure
Trembit’s experience with large-scale multilingual telehealth platforms — including systems serving 250+ languages across diverse and underserved patient populations — has shaped a set of architecture principles we apply consistently:
Build the tiered routing layer from day one. Retrofitting intelligent routing onto a system designed for AI-only or human-only interpretation is expensive. The routing logic should be a first-class component, not an afterthought.
Invest in the STT layer before the translation layer. Most translation quality problems originate in the transcript, not the translation model. Better audio preprocessing and STT selection have a higher ROI than switching MT providers.
Design for human handoff. Regardless of how good your AI translation is, clinical situations will arise that require a human interpreter. The handoff path — dispatching an interpreter, connecting them to the live session, managing the transition — should be as fast and seamless as your primary translation flow.
If you’re building multilingual capabilities into a telehealth platform — or evaluating whether your current translation architecture is adequate for your patient population — Trembit’s engineering team has direct experience with the infrastructure, vendor landscape, and clinical workflow requirements that make these systems work.
Talk to us about your language access requirements.








